By: David Matos
Sharing personal my notes, and experiments with optimizing my real-time Global Illumination lighting buffers. The main goal is to reduce the rendering cost while maximizing final image quality and stability.
 Japanese Urban City Night Pack Environment in Unity
Japanese Urban City Night Pack Environment in Unity
Table of Contents
- Preface
- Upsampling
- Temporal Instabilities
- Upsampling - How to go further?
- How to go even further and beyond?
- References / Sources
Preface
 Full Resolution (1920 x 1080) Global Illumination using Voxel Cone Tracing
Full Resolution (1920 x 1080) Global Illumination using Voxel Cone Tracing
In a Real-Time rendering context, when computing any image-space effects, it’s very common as a performance measure to never compute those effects at full screen resolution. The reason for this is simple, the more pixels we have, the more work we do.
Say our final target resolution is 1920 x 1080. Using this resolution will equate to… 1920 x 1080 = 2,073,600 pixels
That is a lot of pixels! Now what you need to consider is that when doing things at this target resolution (for each of these 2 million pixels) you are going to run a set of shader instructions/operations for every pixel, for the given effect.

Left: Tonemapping Shader Code | Right: Voxel Cone Tracing Code
NOTE: Yes it’s not compiled, but even just looking at the source code we can see the sheer volume of work we are doing for the shader on the right compared to the one on the left.
For some light-weight effects like bloom, or tonemapping the amount of overall work that you’ll be doing per pixel is fairly small.
However for more complicated effects like SSAO (Screen-Space Ambient Occlusion), SSR (Screen Space Reflections), or full on lighting buffers for Global Illumination (either using Ray-Tracing, Voxel Cone-tracing, etc.) The amount of overall work needed for those effects is significant.
The end result is that for a large amount of total pixels, you end up doing a large amount of work and your overall performance plummets.
Now you can cut back on the amount of work you do per pixel, which is a viable strategy. Simplify instructions, reduce operations, precompute certain complicated terms into textures or arrays, etc. Unfortunately though with most of these effects/algorithims you can only simplify it so much. The work is required in order to do the effect in the first place!
So if you can’t reduce the amount of work you do per-pixel, you can reduce the amount of pixels that we do work for in the first place. It’s the easiest and also the most effective strategy.
Again our target resolution is 1920 x 1080 = 2,073,600 pixels. If we reduce the target resolution by half we wind up with the following…
| |
Down from 2 million pixels, to just 500 thousand. That is a pretty nice cost saving! We cut down the amount of work we were doing by half! What happens if we go further by going down a quarter?
| |
Sweet! From 500 thousand to now just a little over a 100 thousand pixels. That is a massive reduction, factor in the work needed for every pixel and we end up with a pretty significant reduction in our final workload needed for the effect.
(NOTE: I would like to point out that there are definetly a lot of over-generalizations that is happening here with this example. Obviously there are some caveats and edge cases as always… but the concept remains the same. The less work you have to do, the better your performance).
However… as attractive as the numbers and instruction counts come out to be, this does come with it’s own set of tradeoffs.
 Raw 1/4th Resolution (480 x 270) Diffuse Global Illumination using Voxel Cone Tracing
Raw 1/4th Resolution (480 x 270) Diffuse Global Illumination using Voxel Cone Tracing
Optimization is a game of tradeoffs, and reducing resolution will introduce some problems…
- Increase the size of pixels, which means increased aliasing/pixelation artifacts.
- Depending on the effect, misalignment of parts of the image no longer align fully with the original.
- Decreased temporal stability with the pixels being much larger, so the more the final pixel value changes between frames the more flickering and instability occurs.
Yikes!
If your effects don’t need to utilize scene depth/normal or any other related buffers this might be fine. But for my case where I’m calculating a lighting buffer that large parts of my project will be lit by… this is not good at all. We can’t use this as is, so we need to do some work in order to make this low resolution image usable.
But wait… didn’t we also mention that we were trying to reduce the workload in the first place per pixel? Yeah… and this is where the true difficulties of optimization come in. It’s a game of tradeoffs, so you need to be careful when doing the work needed to make something usable, because you might end up doing more work in the end than it was to just render the effect at a better resolution in the first place!
So what can we do? Well fortunately… the industry has come up with many solutions that we can employ here to squeeze some more juice out of these shrunken fruits without exploding the final costs.
Upsampling
The basic idea with upsampling in this context is to “cheat” by essentially creating more data, without actually calculating more data. In our case with images we are trying to create more pixels, without actually calculating all of those new pixels (At least not using the original heavy way to calculate those pixels, because it was expensive to begin with!).
It’s also important to note here that we will be covering classic upsampling methods that exist, not machine learning-based techniques like DLSS, FSR, Intel XeSS, etc.
While the end goal is the same, those technologies are aimed at upsampling a final rendered image (not an image within the pipeline that is to help with the final rendered image), and are usually quite heavy.
Upsampling - Chain Setup
I would also like to preface that these upsamples happen in multiple stages, it is not one single pass. This is by design and intentional in order to maximize pixel coverage and performance.
If you have done blur effects, you understand that it’s common to do blur effects in two passes. For example if your doing a wide blur that spans across 32 pixels in each direction, you do it in two passes.
| |
Versus in a single pass, the amount of samples you end up doing is multiplicative…
| |
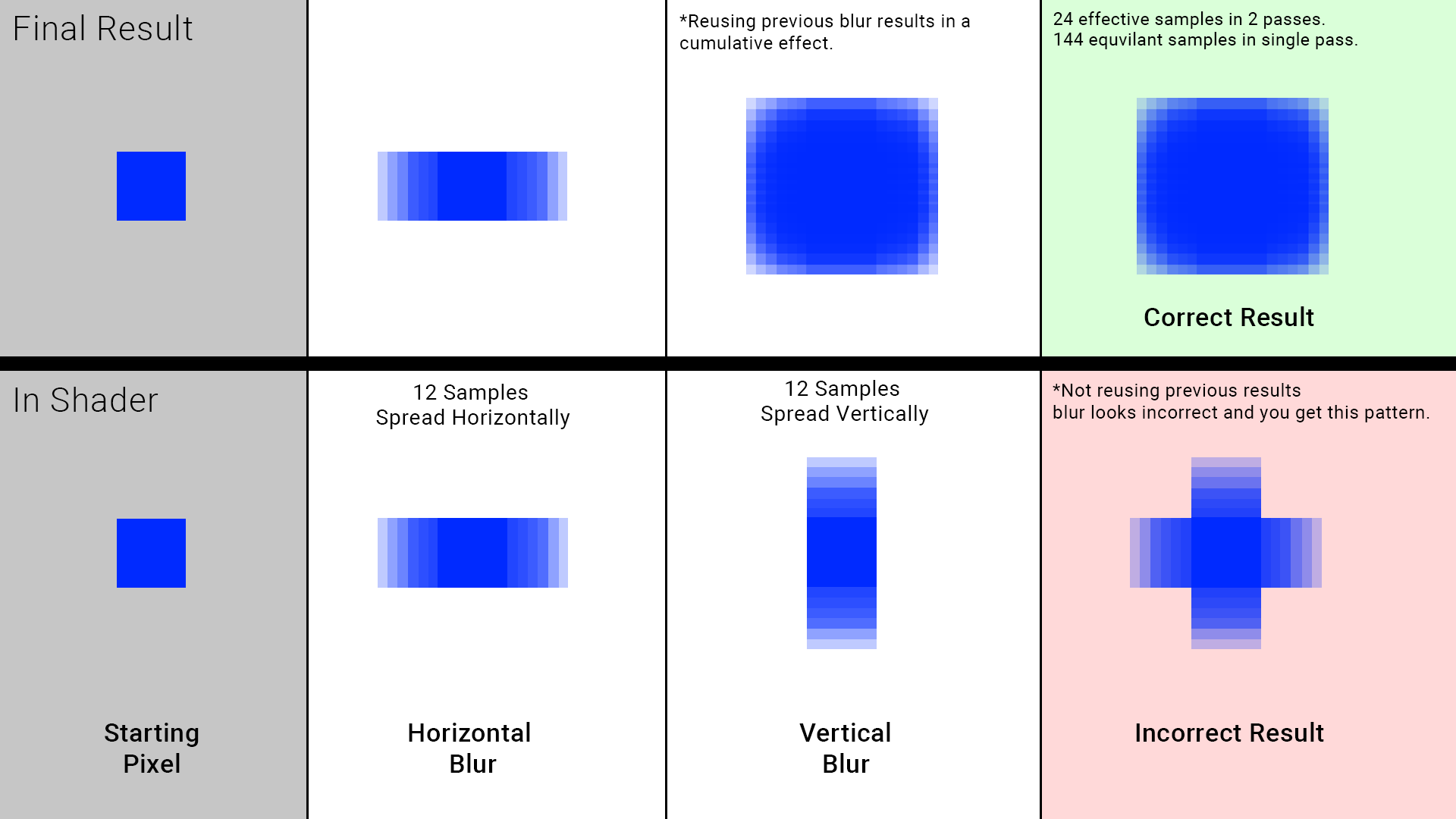
While the upsampling stages are not structured like this exactly, the concept is similar in that we do a relatively small amount of work in a pass. Then this work gets reused again in the next pass, and we do the same thing again spreading things around more but just at a different resolution.
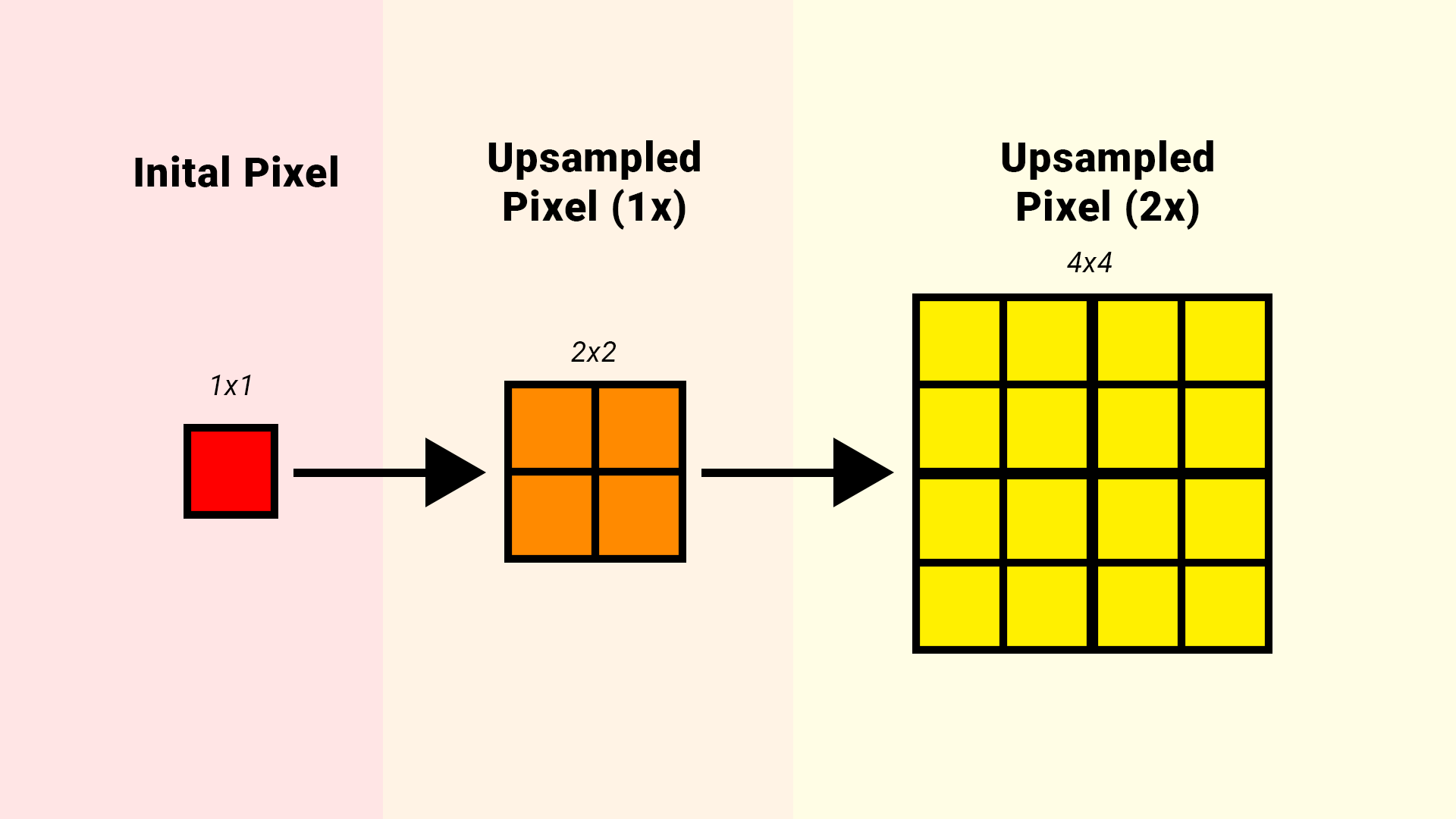
Also, because we are operating on a different resolution this affects our scale since we are working per pixel/texel (Lower resolution means we effectively spread pixels around at a larger scale, higher resolution means we spread pixels around at a smaller scale).
Versus just 1 singular pass where we have to span across many pixel regions in order to get the same result, doing potentially thousands or more samples per pixel to achieve the same result, just like with the single pass blur example.
Each upsample pass/stage is essentially split by a power of two.
- Full Target Screen Resolution (No Upsample Passes)
- 1/2th Target Screen Resolution (1 Upsample Pass)
- 1/4th Target Screen Resolution (2 Upsample Passes)
- 1/8th Target Screen Resolution (3 Upsample Passes)
- 1/16th Target Screen Resolution (4 Upsample Passes)
- 1/32th Target Screen Resolution (5 Upsample Passes)
In practice for 1/4th Resolution…
- (Inital Effect) Calculate effect at 1/4th resolution
- (Upsample Stage 1) Upsample from 1/4th -> 1/2th
- (Upsample Stage 2) Upsample from 1/2th -> Full Resolution
All upsampling related segments utilize this chaining process going forward.

Now lets explore what I did in regards to how I spread those pixels around…
Upsampling - The Basics (Point, Bilinear)
The most basic-basic upsampling we can do is just to duplicate/copy the original pixel we have into the neighboring regions (via Point Filtering).
1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
We can see this does not look good at all for what we ultimately want to achieve. Point filtering just simply copies the data we have into more regions, but it does not look good here.
We get visible blocking and pixelation, and the colors themselves are not properly aligned with the scene like it is with full resolution.
This can be improved by using bilinear filtering which will gradually “fade” between one pixel, and the next within a 2x2 pixel region.
 1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
It’s an improvement… It’s certianly more desirable than the point filtering, but the blockiness is still very visible. Additionally the colors themselves are not properly aligned with the scene like it was with full resolution.
Bilinear filtering does help (and the cost is essentially free, virtually all modern hardware now supports it) but obviously it’s not enough…
We need to cover a wider pixel region!
Upsampling - Wider Blur Filters
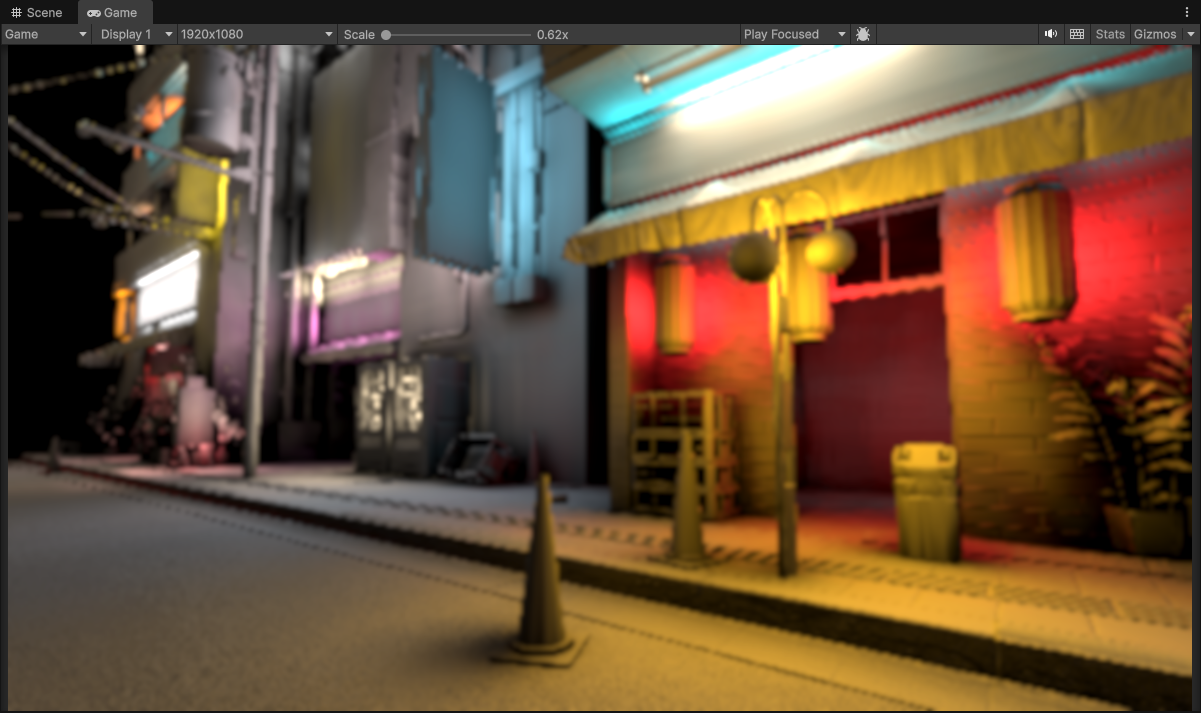 1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
Here I am showing off a 9-tap single-pass gaussian blur. Rendering at a Quarter Resolution (1/4th) with 2 upsample passes, meaning this upsample blur gets applied twice (at two pixel/resolution different scales).
We can see that now the underlying effect is much smoother compared to bilinear filtering. The pixelation artifacts and blockiness are much less visible now. Awesome!
| |
I am using a 9-tap single-pass gaussian blur. Not multi-pass, just single pass but at a very small radius. You could use different variants like a box filter, or a smaller kernel like a 5-tap or a 7-tap hexagonal. We could go wider, which would help mitigate most of the pixelation/blockiness. Unfortunately though we still are left with one big problem.
That being that pixels do not align with the scene well at all. The wider filtering we are doing here just looks like a wierd bloom or blur effect. None of the edge or normal details of the scene are preserved and it only gets worse with lower and lower resolutions.
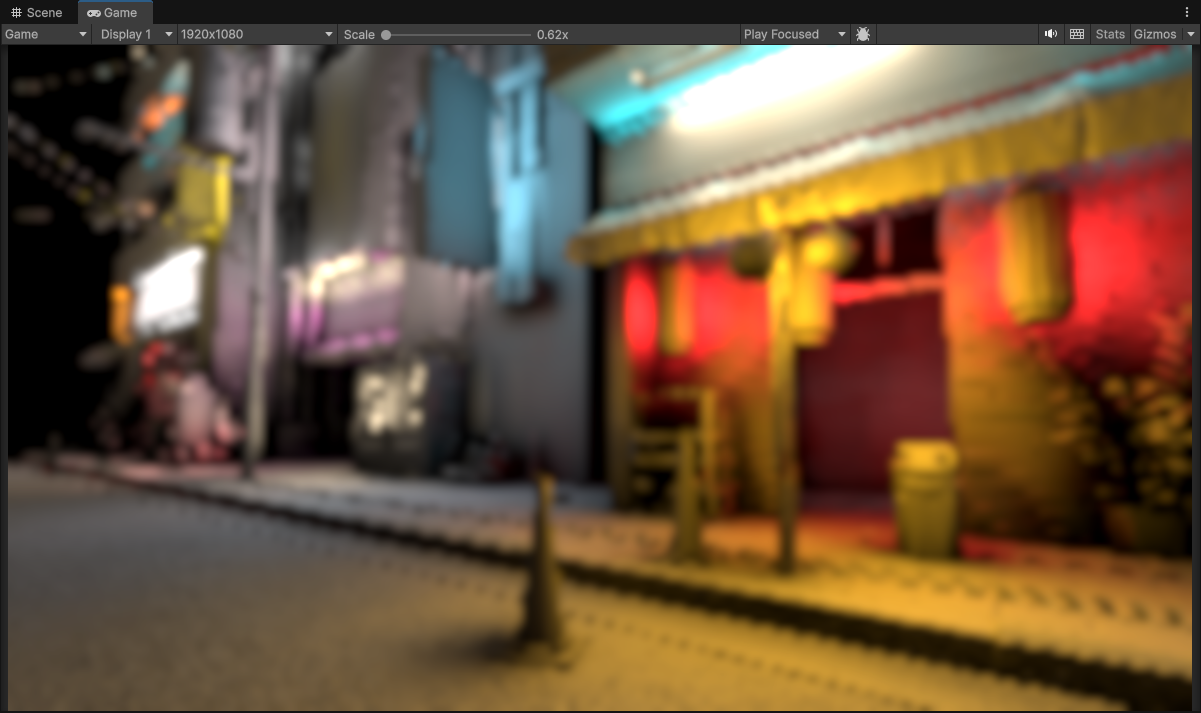 1/8th Resolution (240 x 135) with 3 upsample passes (to 1920 x 1080)
1/8th Resolution (240 x 135) with 3 upsample passes (to 1920 x 1080)
Ok, so mabye instead of just spreading pixels around blindly, we need to control that spread. In order to control the spread we need to determine what spots will recieve a greater spread/blur, and what spots will remain sharp.
So how can we do this?
Upsampling - Depth Aware
Enter depth upsampling.
We don’t throw away what we did before, we just build on it. We need to spread our pixels across to more areas than just that 2x2 region, this mitigates pixelation/aliasing problems, but we need to be smarter as to how to spread those pixels around.
Fortunately, due to the nature of this effect (Diffuse Global Illumination) we already have access to a depth buffer.
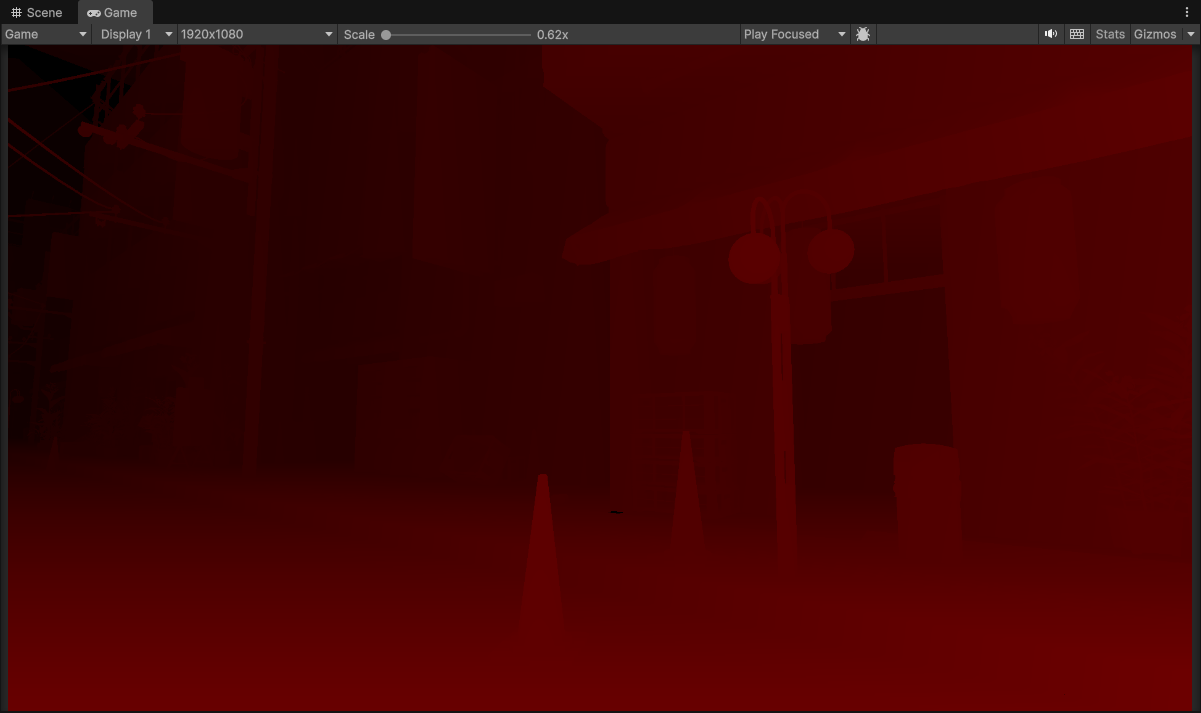 Raw Scene Depth (1920 x 1080)
Raw Scene Depth (1920 x 1080)
The depth buffer essentially tells us where surfaces are in the scene. We used it during our lighting calculations, so let’s also reuse it here to guide our upsampling filter!
By sampling the depth buffer in the same fashion as we were sampling the color for blurring, we can calculate the differences and determine roughly where there are continous smooth/flat surfaces, or if there are large gaps/discontinuities within a pixel region.

The left side is zoomed into a pixel region of the depth buffer where we can see that alot of the pixels here are roughly the same. So when we compute the depth differences between the pixels in this region, it will be small or the same. This means that we should spread pixels around here more easily.
The right side is zoomed into a pixel region of the depth buffer where we can see that there a lot of differences and discontinuity. So when we compute the depth differences between the pixels in this region, it will be large. This means that we should NOT spread pixels around here that easily.
| |
We use the calculated differences between the depth values to weigh (multiply) each of our color taps, and we can see how this affects our blur filter now…
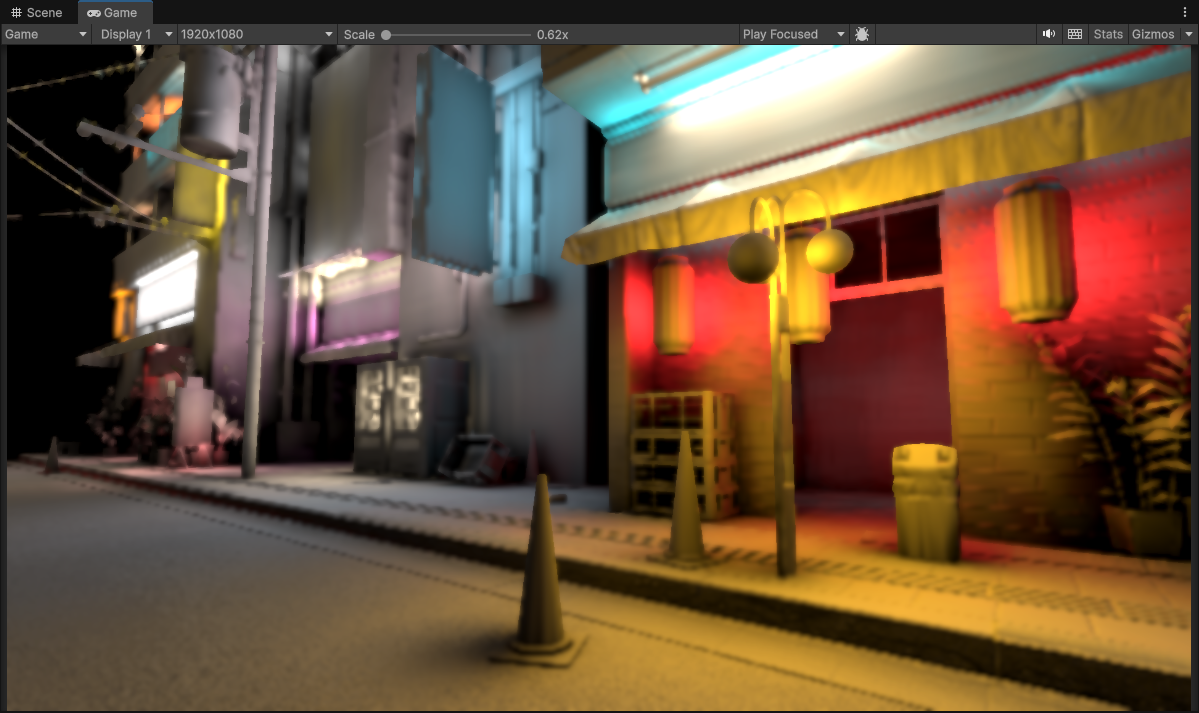 1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
Sweet! We can actually see some of original sharp edges of some of the objects in the scene coming back now!
This is the most common upsampling you will usually see with most depth-based effects, because it’s simple and cheap. There are some derivatives and alternatives that do exist (joint-bilateral comes to mind), but for some effects like volumetric fog, or even SSAO, this is usually where the work ends according to the many tutorials and articles I’ve found online…
Unfortunately I am not satisfied enough with the results here.
Especially for something as complicated as calulating diffuse global illumination like in here, this still wasn’t convincing enough for me (and mabye even for you). There will be portions in my project where most of the scene will be lit entirely by the global illumination buffer, and if we stick with this those areas will just look like a blobby mess. That would infuriate my artists seeing their hard work being crushed, and I don’t want that!
The quality is certainly better than it was without depth, but there were still large portions of the scene here where surfaces that originally had plenty of detail now get smeared over when we compare with the original expensive full resolution buffer.
Full Resolution (1920 x 1080) with 0 upsample passes
So again using depth helps, but it looks like we need more information about the scene in order to better spread our pixels around. Is there another attribute aside from just depth that we can utlize to help align/place pixels even more?
Upsampling - Depth and Normal Aware
Enter depth-normal upsampling. Once again we build on the work we did before with the depth aware upsampling, but we add an additional attribute… a normal buffer.
The scene depth buffer helped us find and retain some of the geometry edges in the scene, but we will also use scene normal buffer to help with finding more geometry edges, and mabye even some normal mapped details (as long as normal buffer is not reconstructed from depth).
Just like the depth buffer, we also used the normal buffer in our inital lighting calculations to find the orientation of a surface and calculate the lighting of that point. Lets reuse it again here to guide our upsample filtering.
 Scene Normals [0, 1] range (1920 x 1080)
Scene Normals [0, 1] range (1920 x 1080)
Normals tell us the orientation of surfaces in a scene.

The left side is zoomed into a pixel region of the normal buffer where we can see that alot of the pixels here are roughly the same. So when we compute the normal differences between the pixels in this region, it will be small or the same. This means that we should spread pixels around here more easily.
The right side is zoomed into a pixel region of the normal buffer where we can see that there a lot of differences and discontinuity. So when we compute the normal differences between the pixels in this region, it will be large. This means that we should NOT spread pixels around here that easily.
| |
Implementing it very similarly here with the depth, we just do 9 taps (or whatever amount your underlying filter is doing) with normal, then calculate the deviations that happen between the pixel regions and we weigh these with our depth.
 1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
1/4th Resolution (480 x 270) with 2 upsample passes (to 1920 x 1080)
Nice! We can see now that this is a significant improvement over just depth-aware upsampling. Geometry edges are almost fully preserved now, and much less pixelation artifacts are visible at the same time.
This is looking much better, in fact this gives me enough confidence in that I might push things further by dropping the resolution to 1/8th and see how things hold up.
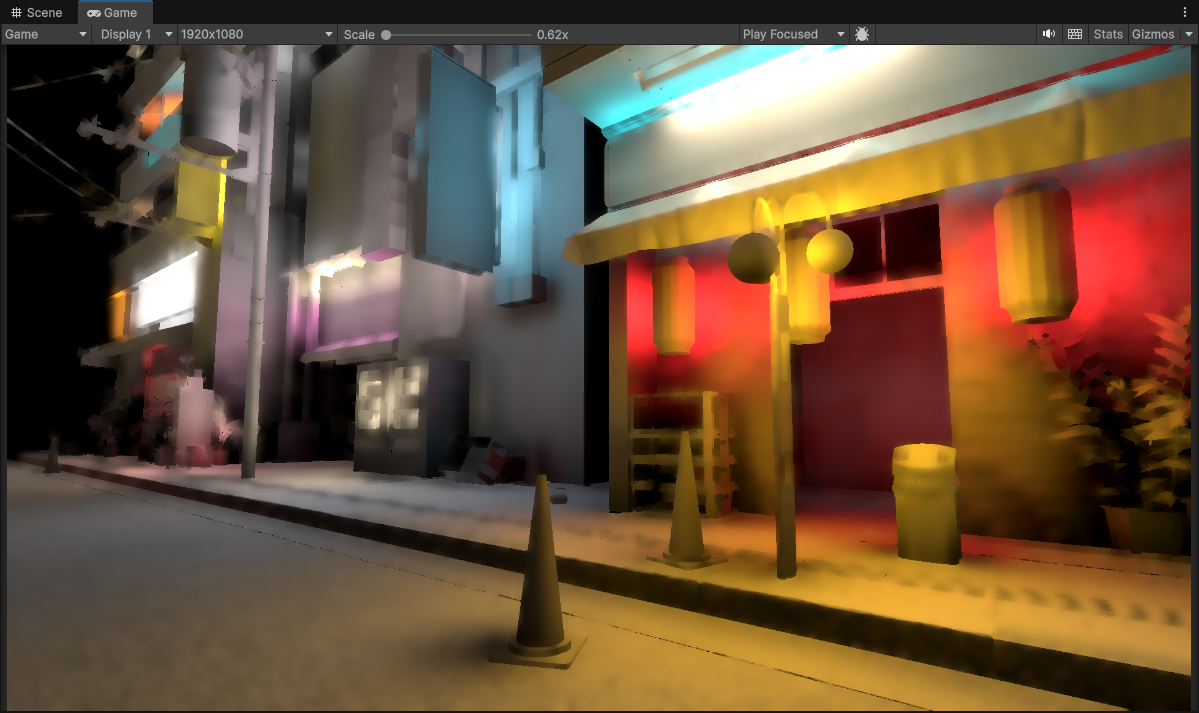 1/8th Resolution (240 x 135) with 3 upsample passes (to 1920 x 1080)
1/8th Resolution (240 x 135) with 3 upsample passes (to 1920 x 1080)
Surpisingly well, some pixelation is more visible now of course but the depth-normal aware upsampling is doing a fantastic job of keeping all of the geometry edges and some of the normals sharp and visible. It’s a significant improvement!
But… there are still some things that bug me even at 1/4th resolution (480 x 270), and the issues get more visible when dropping down to 1/8th now. Geometry edges are kept in-tact but most of the original normal-mapped details of the scene are mostly gone now. Pixelation details also are starting to become even more visible.
Is there a way to mitigate those pixelation artifacts some more, and mabye even bring back normal-mapped details?
Spoiler: Yes!
Optimization Bonus
Now I would like to point out here that depending on your setup this depth-normal upsampling will cost an extra render target, which means more texture lookups to factor in this normal buffer read like you see in this implementation.
An additional optimization here that you can that is to pack a singular RGBA render target with both depth (16-bit half precision) and normal (encoded into a 2 channel using octahedron/spherical coordinates/etc) which gives you a depth-normal render target.
- RG: Depth (Half Precsion 16-bit)
- BA: Normal (Encoded into 2 component 16-bit)
RGBA32 or even RGBA64 can work if you desire more precision/quality at the expense of memory.
Either way combining these into a single depth-normal render target would reduce the texture fetches by almost half, at the expense of adding additional instructions for unpacking the render target for use in the filter. (You are basically trading memory for ALU here. Fortunately with most modern hardware now being more capable, this is prefered so that way you are not bound by memory access speeds with texture reads). I recommend doing this!
| |
| |
Temporal Instabilities
Now, quick spoiler there is still a couple of more additional stages needed to improve the spatial quality even more but I wanted to take a pause real quick because there is something very important here that we need to consider before moving forward…
Remember that context wise we are in a game setting (or a real-time context). The camera will be moving and changing, so will the scene… so how does our work hold up when the camera starts to move?

1/8th Resolution (240 x 135) with 3 upsample passes (to 1920 x 1080)
Yikes! Not good at all.
There is a lot of flickering, and the lower we go resolution wise the worse the artifacts and flickering get…

1/16th Resolution (120 x 67) with 4 upsample passes (to 1920 x 1080)
This does make some sense… If you remember one of the tradeoffs I mentioned with reducing resolution is that since pixels become larger, that means when a pixel changes between frames it’s much more visible.
Well that’s not good. Seeing these problems might make you backtrack and not attempt to reduce the resolution any further, but then you’d lose out on the performance gains! We are trying to optimize this and make it run well, and look good!
So… is there a way to fix this flickering and improve quality at the same time?
Temporal Instability Solutions: Temporal Filtering?
Fortunately the industry has come up with a way to resolve such an issue. The technique is called temporal filtering. The idea is that you use previous frames and reproject into the current frame to gradually fade in any new pixel changes that occur.
Ok that sounds good, and I did go forward and implement this…

1/8th Resolution (240 x 135) with 3 upsample passes (to 1920 x 1080) and Full Resolution Temporal Filtering
Ok good, this definetly solves a lot of the flickering!
But…
Not only am I seeing some problems here that I find quite destructive to the final image quality, the flickering is still visible in some spots. Remember that optimization is a game of tradeoffs, temporal filtering just like any solution will introduce it’s own set of problems. So what are they?
- Temporal Filtering relies on good Temporal Resolution. In english this means that the more frames you have, the better the quality/resolve because the differences between frames get much smaller (and quicker). However! In games you often don’t have the greatest temporal resolution anyway (low FPS), and it can fluctuate! So the resolve worsens especially if you are on low spec hardware! (or if your app is poorly optimized)

- Temporal Filtering introduces ghosting/trailing artifacts. While additional attributes and conditions can be introduced to mitigate these artifacts, they will still be present in your image and you will have to constantly tweak and fight these artifacts that still muddy up your image quality in the end.
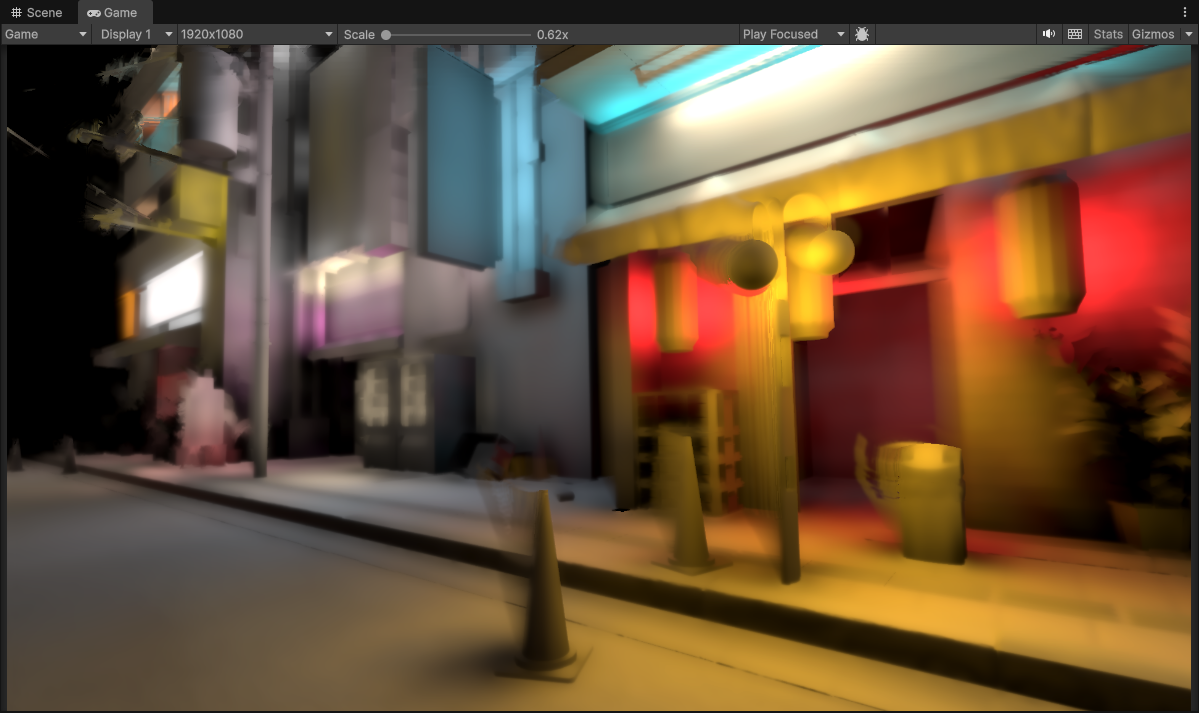 1/8th Resolution (240 x 135) with 3 upsample passes (to 1920 x 1080) and Full Resolution Temporal Filtering
1/8th Resolution (240 x 135) with 3 upsample passes (to 1920 x 1080) and Full Resolution Temporal Filtering
 Very visible trailing artifacts… eughhh!
Very visible trailing artifacts… eughhh!
I mentioned that these trailing/ghosting artifacts can be mitigated in a number of ways…
- Reducing the overall weight of the temporal filtering (less frames being blended together).
- Using a velocity buffer, so any regions with fast or rapid pixel changes would have a reduced temporal blending.
- Using depth rejection, any pixels with drastically different depth values between different frames would have reduced temporal blending.
I have tried all of these, but my issue with most of these is while they can help, in the end most of these boil down to selectively reducing the influence of the temporal filter in select parts of the image. So you will end up bringing back the flickering at the expense of fighting some of these temporal artifacts in the first place.
I also tried a different strategy in an attempt to combat this problem, which was to try doing the temporal filtering at 1/8th resolution instead of at full resolution (1920 x 1080). Any artifacts brought on by the temporal filtering natrually would get blurred/smoothed out with the depth-normal aware upsampling chain that happens after.
Though I also suspected that some of the flickering artifacts with the upsample would come back when we do the temporal filter at a lower resolution. Since now we can no longer fade pixel changes at a finer scale with the higher resolution to alleviate some of those flickers in the first place.

1/8th Resolution Lighting and Temporal Filtering (240 x 135) with 3 depth-normal aware upsample passes after (to 1920 x 1080)
Yep, so some of the flickering artifacts have came back, that makes sense since now we are no longer doing the temporal filter at full resolution. So it can’t take care of some of the flickering artifacts brought on by the upsampling.
As a plus atleast it seems the sharp trailing artifacts appear to be mostly gone now, but there seems to be some other oddities going on…
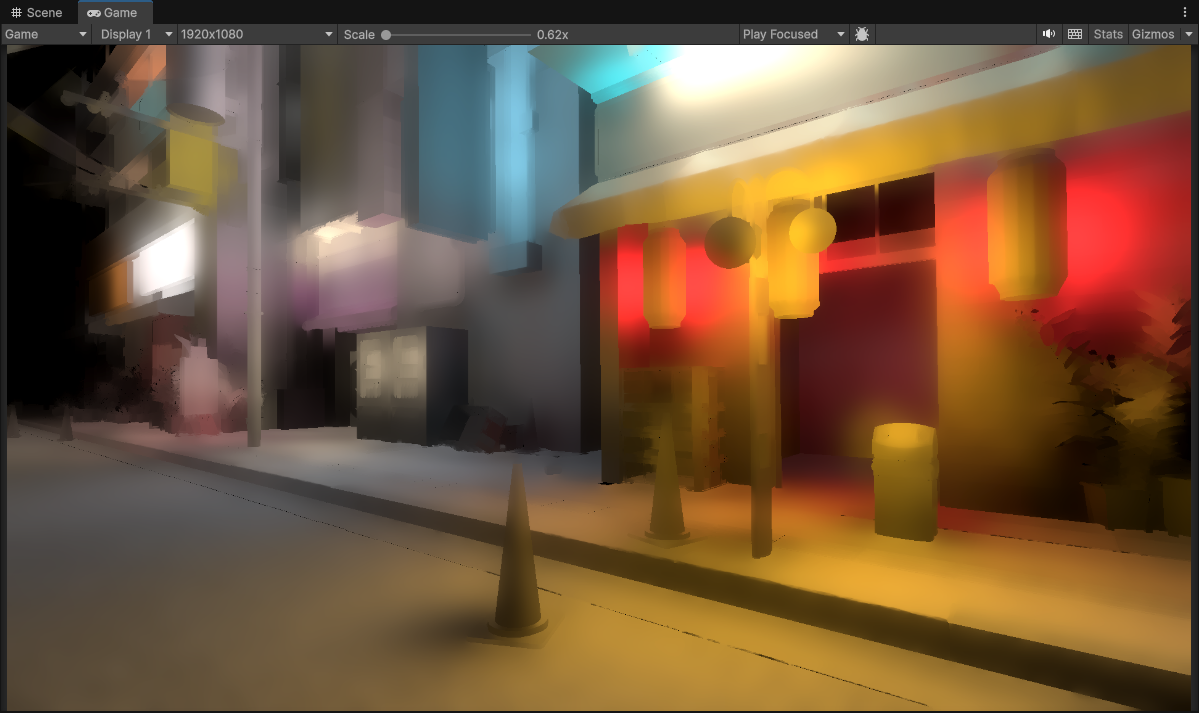 1/8th Resolution Lighting and Temporal Filtering (240 x 135) with 3 depth-normal aware upsample passes after (to 1920 x 1080)
1/8th Resolution Lighting and Temporal Filtering (240 x 135) with 3 depth-normal aware upsample passes after (to 1920 x 1080)
It appears that the image overall has gotten a lot softer. In addition also I am still seeing ghosting trails behind objects like I was before.
 Smoothed out sharp trailing artifacts from before, these ghosts are more visible thanks to the blurring
Smoothed out sharp trailing artifacts from before, these ghosts are more visible thanks to the blurring
The only difference now is that it’s less sharp and more blurred out. It is an improvement over doing it at full resolution but even with some more tweaking these ghosts are still very visible and contribute to a much softer final image. Not only that I still have flickering!
As a result most of these problems were enough to make me want to avoid using Temporal Filtering altogether. It ended up creating more problems than it was intended to solve so temporal filtering for me is out of the window here. There has to be another way to somehow smooth out these results without resorting to temporal filtering and the problems it creates.
Back to the drawing board…
Investigations into Temporal Instabilities
I was geuinely curious as where this source of instability/flickering was coming from and if there was any kind of solution to solve it.
The global illumination technique I am using here is called Voxel Cone Tracing. I won’t explain what it does because that is not what this article is about (and it would take too long), but the algorithim itself does not introduce any inherent noise or a large amount of instability/flickering with how I have it setup (no noise/stohastic sampling).
So the flickering/instability has to be coming from somewhere else…
I decided to have a look at the other componets that get used to calculate the lighting. The main buffers that get used in the lighting calculations are the depth and normal buffers. If we look at the raw depth and normal buffer we are using for our inital lighting calculation, they look fine in motion.


Left: Full Resolution Depth (1920 x 1080) | Right: Full Resolution Scene Normals [0, 1] range (1920 x 1080)
But wait, we are looking at the full resolution buffers here, and the lighting gets calculated at a reduced resolution. Ok, so let’s look at the buffers when it’s being used in that low resolution context directly…


Left: 1/8th Resolution Depth (240 x 135) | Right: 1/8th Resolution Scene Normals [0, 1] range (240 x 135)
Interesting… there is a lot of flickering and instability happening here, why?
Well this is because when we are calculating lighting at a low resolution, we are using these high resolution buffers as-is. This is a problem because we can’t use it at the full resolution (we are working at 1/8th resolution) so only portions of it gets used. As a result we actually wind up skipping pixels!
I’ll show you what I mean.
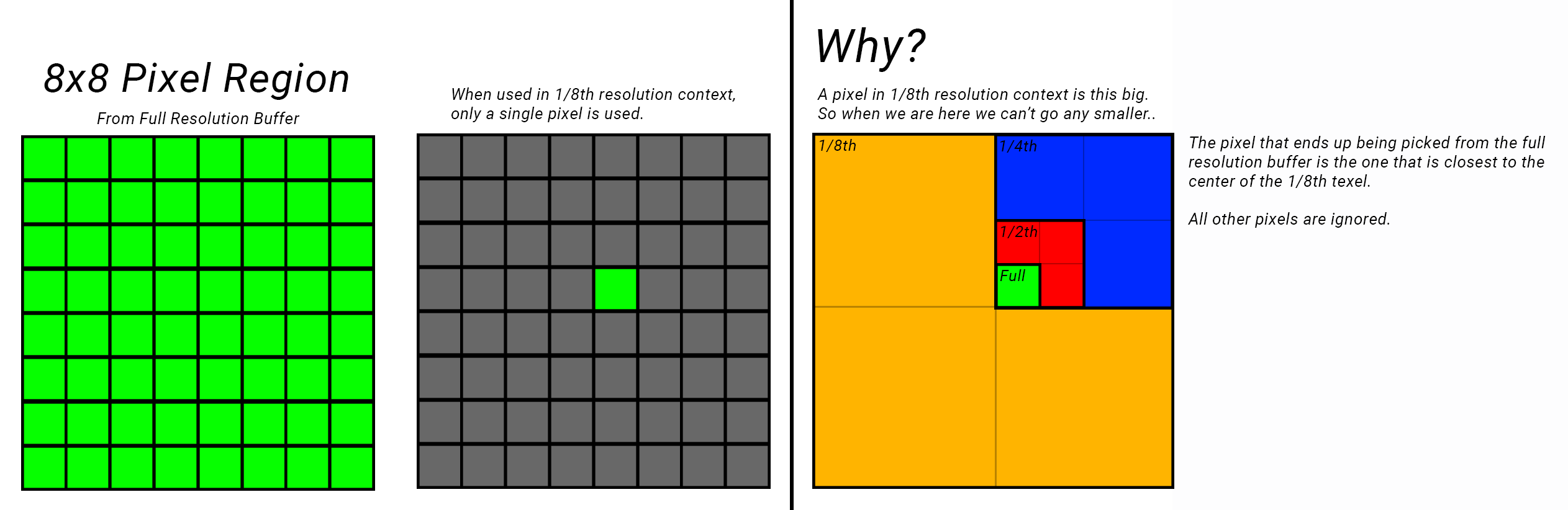
So here we are calculating at 1/8th resolution, when we just use the full resolution buffer as is, turns out it’s picking only a single pixel from an entire region essentially 8x8 pixel region. Out of 64 possible pixels we are just picking out only 1 pixel!
As a result this leads to the flickering that we are seeing, because now the changes between pixels are much more drastic leading to this increased aliasing and flickering. This is also happening in our upsampling stages as well since we are using low resolution depth/normals to check differences with the high resolution variants.
Ok, is there a way we can actually utilize those other 63 pixels that are just flat out being skipped?
Temporal Instability Solutions: Downsampling?
So before we can use our buffers in the 1/8th resolution context, we need to actually prepare them so they can be used in that 1/8th context properly. Downsampling can help us with that.
Downsampling is about taking a large set of data, and effectively “compressing” it down to a smaller set. It’s essentially the reverse/opposite of upsampling we were doing earlier.
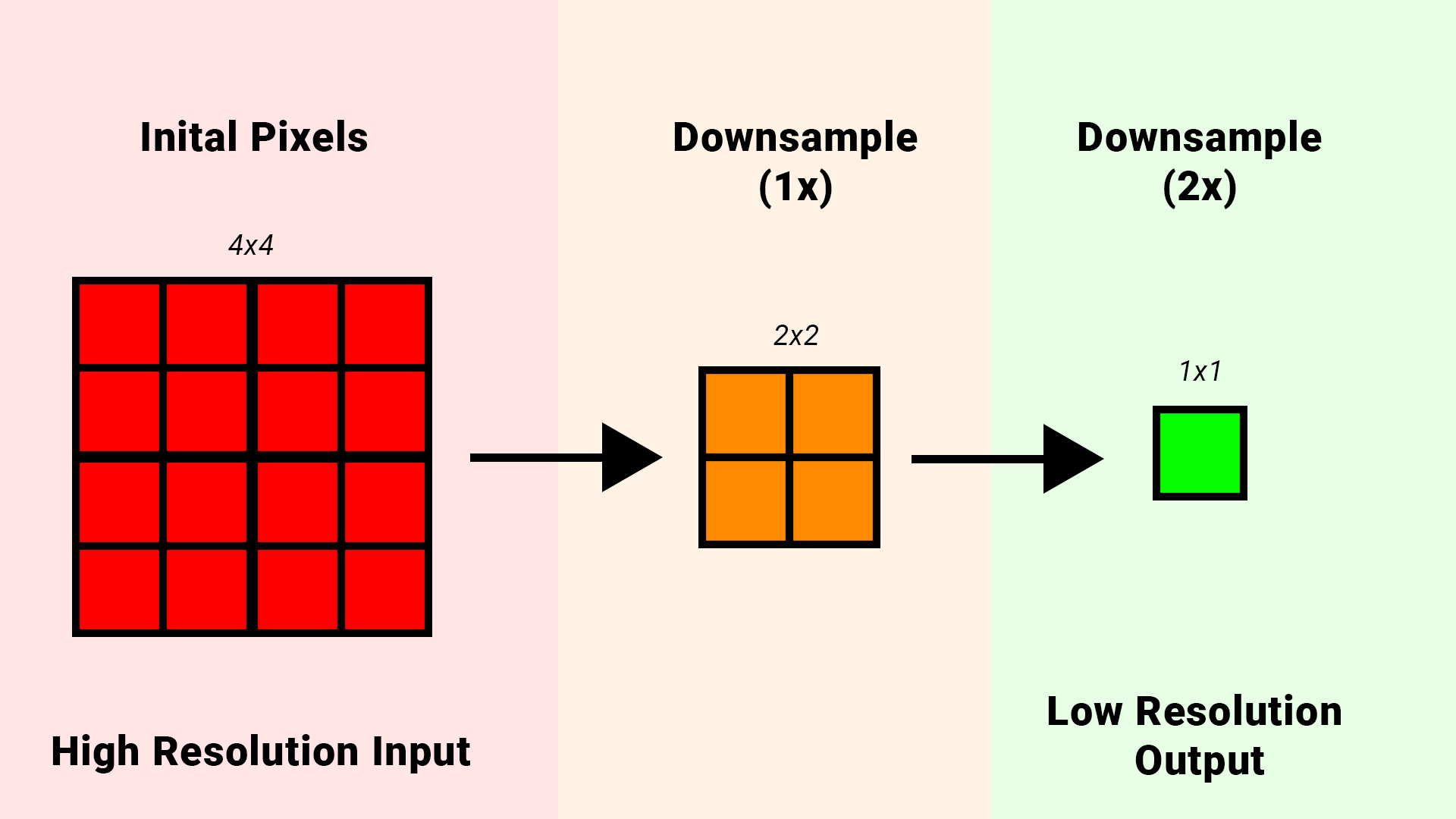
The simplest and most common downsampling algorithim used is just a simple average. Essentially you take any given number of samples, add them together and then divide by the sample count.
| |
Notice how there are some outlier samples in the set (7) but due to the other larger quanity of numbers that are similar in range the final averaged value comes out roughly to 4 - 5.
In the context of pixels/images, if a lot of pixels remain roughly the same then the final value will virtually be the same, but if there is some outliers in the set the influence of those samples natrually will get reduced/averaged out. This is an interesting behavior because one of the problems I mentioned that comes from reduced resolution is that pixel changes become more visible. If the surrounding pixels are mostly the same then the pixel changes will get averaged out.
So it sounds like there is an inherent temporal behavior happening here… Okay that seems sound… why not use it for those scene buffers as well.
In my pipeline I introduce passes now where I downsample both scene normal buffer and depth buffer so I can prepare them for use in the low resolution lighting calculations. It’s similar to the upsampling chain setup, but I just do it in reverse now for downsampling.

NOTE: This was my inital downsampling pipeline, however an optimization that I mentioned earlier that you can do is to pack both depth and normals into a single RGBA32 render target. This would save memory (and texture fetches later) and also simplify the pipeline here to just 1 render target that gets downsampled. Reducing draws and shader invocations, I recommend doing it.
Now for my downsampling I just use a very simple 2x2 downsample average. Different downsampling filters could likely be utilized here but I wanted to start simple.
| |


Left: 1/8th Resolution Downsampled Scene Depth (240 x 135) | Right: 1/8th Resolution Downsampled Scene Normals [0, 1] range (240 x 135)
Applying the downsampling filter chain, we can see that our buffers look much softer now. Importantly I am no longer seeing any visible pixelation or aliasing artifacts in a still frame.
Ok that’s a good sign, now lets see how this looks in motion now…


Left: 1/8th Resolution Downsampled Scene Depth (240 x 135) | Right: 1/8th Resolution Downsampled Scene Normals [0, 1] range (240 x 135)
Ooooo! So after applying a downsample filter to our normal buffer (and depth buffer), much of the flickering that we saw before now actually vanishes. This is promising…
So now I’m left with these scene buffers downsampled to the resolution that the lighting gets calculated at (1/8th, 240 x 135), so lets use them now for calculating lighting (and the upsampling stages) and see what happens… (Looking at the still frame first)
 1/8th Resolution (240 x 135), using Downsampled Buffers and with 3 upsample passes (to 1920 x 1080)
1/8th Resolution (240 x 135), using Downsampled Buffers and with 3 upsample passes (to 1920 x 1080)
Ok interesting… I can actually see a lot less pixelation now compared to before even in a still frame, and the lighting results are slightly different. Some spots do appear wierder (I’ll explain why that is in a bit) but for the most part everything still looks pretty good.
So how does this look in motion now?

1/8th Resolution (240 x 135), using Downsampled Buffers and with 3 upsample passes (to 1920 x 1080)
Wow, massive difference! This almost looks like the results we got when we implemented the full resolution temporal filtering! Granted there is still some flickering we can see, but there are no trails/ghosting artifacts that we have to deal with.
We can reduce the resolution much further and pile up more progressive upsamples to see how things hold up…

1/16th Resolution (120 x 67), using Downsampled Buffers and with 4 upsample passes (to 1920 x 1080)
Not bad! It remains pretty stable temporally, even when we are as low as 1/16th resolution!
Of course it’s not perfect. The flickering is much more noticable especially when we go to this low of a resolution, and we can make out some funk in the lighting quality. That’s because downsampling is not a perfect solution.
Every solution introduces their own set of issues, but I find the issues here much more tame and less visible than temporal filtering artifacts like ghosting/trails that we saw before that we had to fight with (and being bound by temporal resolution). Importantly for me, the scene remains sharp even in motion.
Now earlier I mentioned that our lighting looks a little different (might even be considered worse in some areas), I want to explore that further.
Downsampling - Drawbacks
With downsampling and using the averaging algorithim, we reduce a set of pixels down to one, and effectively construct a fresh and unique new pixel value. Ok sure that makes sense, that is what we were trying to do in order to gain temporal stability in the first place.
But this is why some graphics programmers might shy away from doing this (and for good reason).
The reason being that with downsampling (and the averaging), you are creating a fresh new pixel out of a set of original pixels. In the context of depth, you are taking a set of original depth values, are a creating a fresh new unqiue depth value. A depth value that of which does not exist in the original depth buffer. (Same with the normal buffer)
If you recall back to the basic averaging math example from earlier…
| |
The final averaged value is 4.917, which is close to 5 but 4.917 is a value that never actually existed in the original set.
Technically this means that if you are doing a lighting calculation, you use depth to reconstruct the position of a pixel so you can calculate the lighting at that point.
When you introduce downsampling, that depth value actually changes so when you calculate position now, it actually gets shifted and that means the lighting at a given surface point is actually not 100% accurate. It’s in the wrong spot! Either its slightly pushed forward or slightly pushed backwards depending on the surrounding pixels of that region. In our image in some spots this can actually introduce a “halo” around some objects in the foreground.
 Visible halo-ing around the cone
Visible halo-ing around the cone
This also applies to the normals as well, surface normals within an area get averaged to form a new normal value. This normal value is then shifted in a different direction leading to slightly different lighting results for some surfaces.
Now if this is a concern, there are different downsampling filters that exist. For instance with depth it’s common to actually use a min or max filter since those will pick either the closest (or farthest) pixel that was in the set and use that. However Min/Max does not average out pixel changes across an area so that inherent temporal behavior I described with averaging does not happen.
This is why temporal filtering is also attractive to some graphics programmers (and by extension, why some of the industry is pushing for it). It is because it does a better job at retaining “correctness” or accuracy of those original samples.
Some even take it as far introducing “jittering”. If you remember also from earlier when I described the inital problem of how we only picked 1 pixel out of a region of 8x8 pixels…
With jittering, we still ultimately choose 1 pixel from the region, but with the concept of time/temporal in the mix we actually change which pixel we choose within that region every frame. Across 4 frames we chose 4 different pixels from that region. Natrually the temporal filtering will blend these pixels together and we retain correctness.
But that is still 4 pixels out of a total of 64 in that 8x8 region, we could introduce more jitter samples across time. But covering the full 64 samples across 64 frames requires a lot of temporal resolution. Temporal resolution that often we don’t have, considering the common target framerate for games are 60 frames a second, and a lot can change in a second!
You could also try not dropping the resolution that far. For example just going down to a quarter resolution (rather than 1/8th) gives you a 4x4 pixel region of 4x4 = 16 pixels. Less samples that you need to cover, but still thats 16 frames of blending needed across time.
An interesting solution that the industry is also adopting is a combination of these two ideas so to speak.
This amounts to things like Spatio-Temporal upsampling and this interestingly actually starts leading into the core ideas behind upscalars like FSR, DLSS, Intel XeSS. Where you have a spatial component of the filter that takes care of smoothing out pixels across an area, and the temporal component takes care of smoothing out pixel changes across time.
However… as I pointed out, temporal filtering at large still introduces visual issues that I’m not a fan of so I would like to avoid it if I can. I may apply TAA at the end of my final graphics pipeline but I don’t want to apply a temporal pass to this or any other effects if I can help it. Doing that would stack the temporal artifacts you get by the end of the frame that TAA would have to cleanup (and it may not clean it up completely), and I want to avoid that, so it’s important that these effects look good and stable on their own.
But objectively, while the downsampling does help eliminate alot of the inital flickering. You could combine it with a light-weight temporal filter to cleanup the flickering completely.
As for me I just went forward with downsampling as my main solution for temporal stability here as the gains were to significant to ignore. Outside of that I don’t know any other techniques or solutions that could be employed here. (NOTE: If you do have a solution or know of one, PLEASE LET ME KNOW!).
Temporal Solution Comparisons
Left: 1/8th Resolution (240 x 135) With Full Resolution Temporal Filter (1920 x 1080) | Right: 1/8th Resolution (240 x 135) With Downsampled Buffers
Left: 1/8th Resolution (240 x 135) No Downsampled Buffers | Right: 1/8th Resolution (240 x 135) With Downsampled Buffers
Left: 1/16th Resolution (120 x 67) No Downsampled Buffers | Right: 1/16th Resolution (120 x 67) With Downsampled Buffers
So to conclude this section I want to share what the pipeline looks. You might have missed it but I also mentioned that the downsampled buffers also get used in each of the upsampling stages. They are all stored in the mip levels so with each progressive upsample we use the respective mip level (that holds the downsampled render target) which helps alot with improving temporal stability in the final image. We also pointed out that it improves the spatial quality as well, reducing pixelation on the final frame.
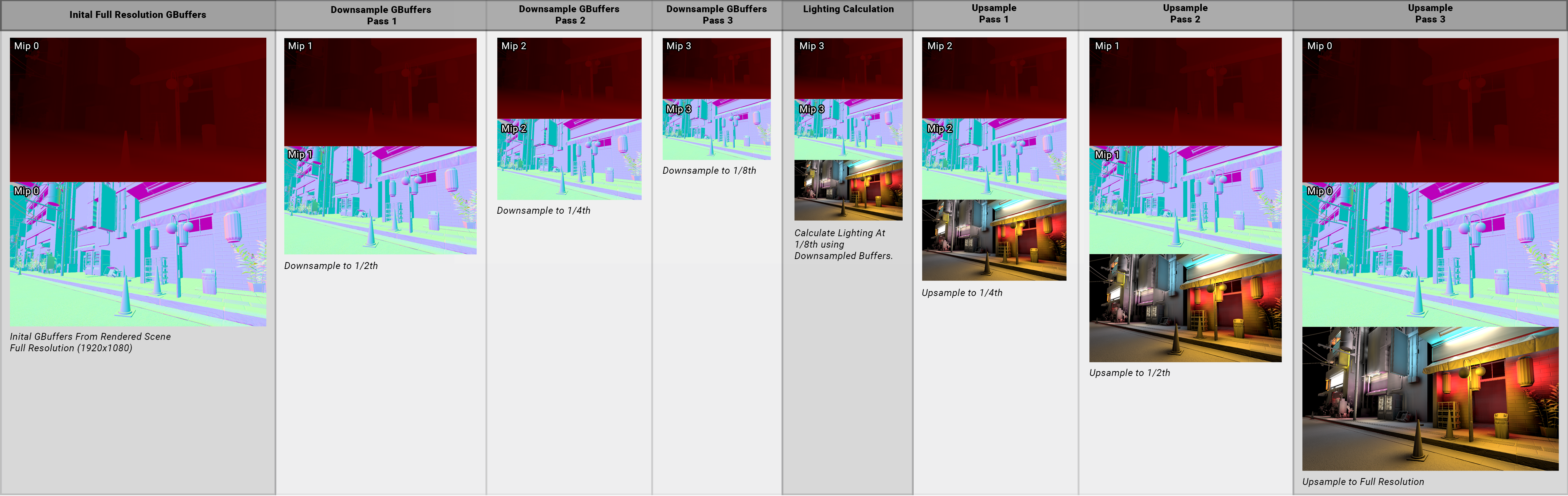
Upsampling - How to go further?
1/8th Resolution (240 x 135), using Downsampled Buffers and with 3 upsample passes (to 1920 x 1080)
Shifting gears back to improving the spatial quality of the lighting (now with the temporal component at a decent spot), even with the downsampled buffers and the best upsampling I was able to find, this still was not convincing enough for me even at lower resolutions because surfaces still get smeared too much!
So we need to take a step back and think as to why this is really happening. Why are the surfaces looking so smeary/blurry?
Well when we do lighting, surface position matters a great deal. That is mostly already covered though fortunately thanks to the depth-aware upsampling that we do.
Another factor that significantly affects the lighting of a surface is it’s orientation, or normal. The depth-normal-aware upsampling again helps with this but it’s still not enough… so what’s missing?
Do we need another scene attribute?
Well for diffuse lighting we have the surface position, and the surface normal. We do have surface roughness and metallic, but those are meant for specular and don’t have an effect on the actual diffuse term… mabye surface occlusion?
Sure lets try that. Most materials/objects in my project have an authored ambient occlusion map, let’s try factoring that in.
 Full Resolution (1920 x 1080) Scene Material Occlusion
Full Resolution (1920 x 1080) Scene Material Occlusion
We apply occlusion just multiplying the final lighting buffer with it.
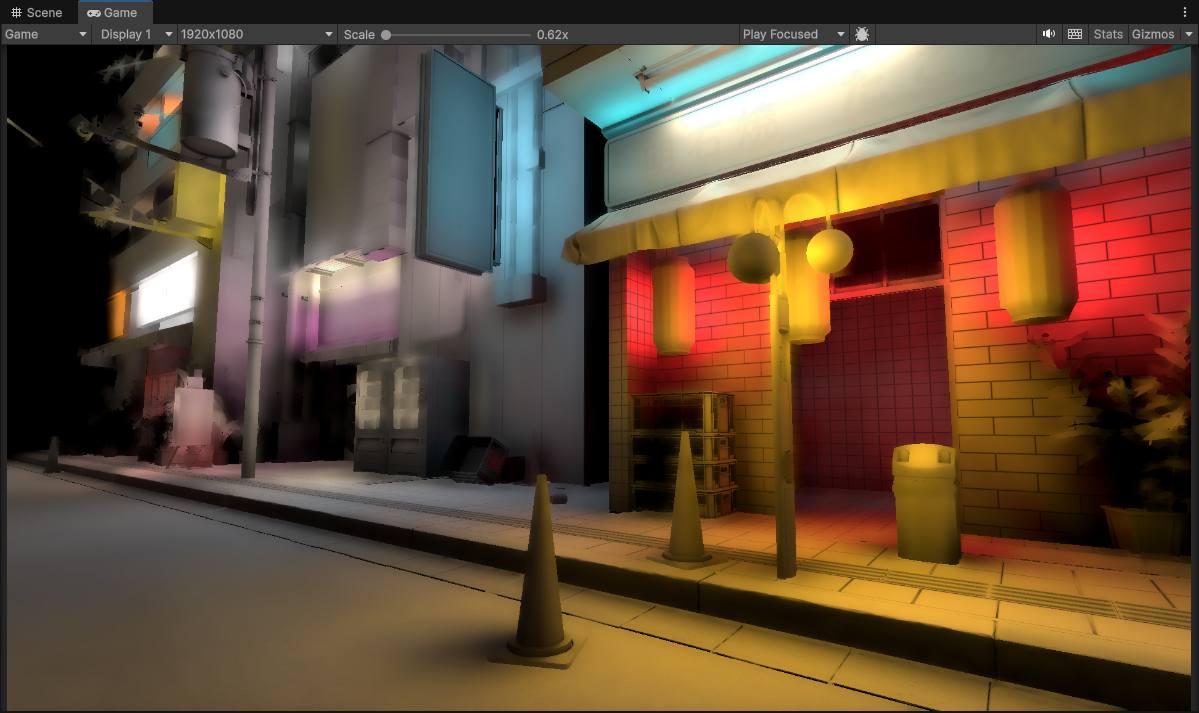 1/8th Resolution (240 x 135), using Downsampled Buffers and with 3 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
1/8th Resolution (240 x 135), using Downsampled Buffers and with 3 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
Ok… that’s not bad, it definetly helped!
But it’s not good enough… (you might be rolling your eyes at me by now, but bear with me :D)
 1/8th Resolution (240 x 135), using Downsampled Buffers and with 3 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
1/8th Resolution (240 x 135), using Downsampled Buffers and with 3 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
We can still see underneath it that things are getting blurred and smeary. Occlusion is helping by adding some more detail to surfaces, but some objects in the scene are still turning into a blobby mess.
What’s worse though is that some object’s in my project don’t (and wont) have authored ambient occlusion maps, so those will be left out completely! We don’t have any other scene attributes we can really utilize here to push things further, so we are kind of stuck.
We have to look deeper, and really examine why things are blurred and smeary.
Now conceptually for each pixel we only have a single color that we are juggling around a given image region. We are much more selective now as to where we place this color value. But it’s only just a color value… mabye we need more than just 1 color value per pixel?
Ok sure, having more color values would help, but in order to get more data shouldn’t we increase resolution to do that?
We can… but that leads to worse performance, and that goes against what we were trying to do in the first place, which was reduce resolution and do all this upsampling!
Ok… is there another way we can increase the amount of data without doing that?
Spherical Harmonics
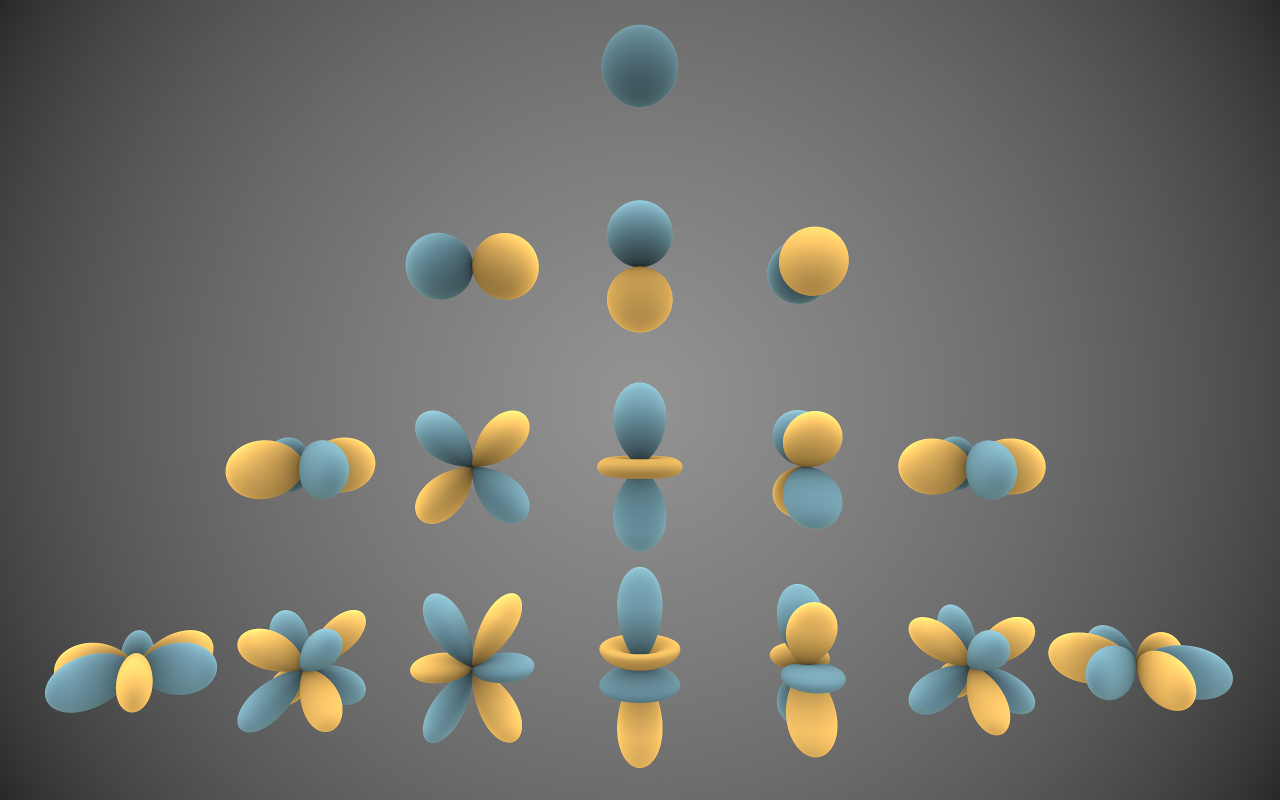 Image by Iñigo Quilez illustrating the directions that Spherical Harmonics can represent. 3 orders are represented here from top to bottom. Order 0, 1, 2, 3.
Image by Iñigo Quilez illustrating the directions that Spherical Harmonics can represent. 3 orders are represented here from top to bottom. Order 0, 1, 2, 3.
You may have heard or know of it, mabye not. The fancy name does tend to scare away quite a few people but it’s fairly simple in practice.
The general problem we are faced with is that we need to introduce more data in order to shade more accurately. We need more lighting information at a given pixel than just one single color. This is where spherical harmonics can help us.
Spherical harmonics take a given spherical signal/data, and sum it up to a set of coefficents that you sample later. (You can think of them almost like a really small cubemap). Spherical Harmonics have orders, the more orders you have the more data/coefficents you end up with (and effectively better quality).
I’ve set up an example in a different project here to demonstrate Spherical Harmonics. It is a simple environment that will be lit entirely with an HDRI cubemap that is projected into spherical harmonic coefficents. Starting with Order 0, graphically it’s the single top element.

This single float3 coefficent is the average color of the whole lighting environment. Technically this is exactly what is happening with our current lighting setup, it is just a single color we are throwing around.
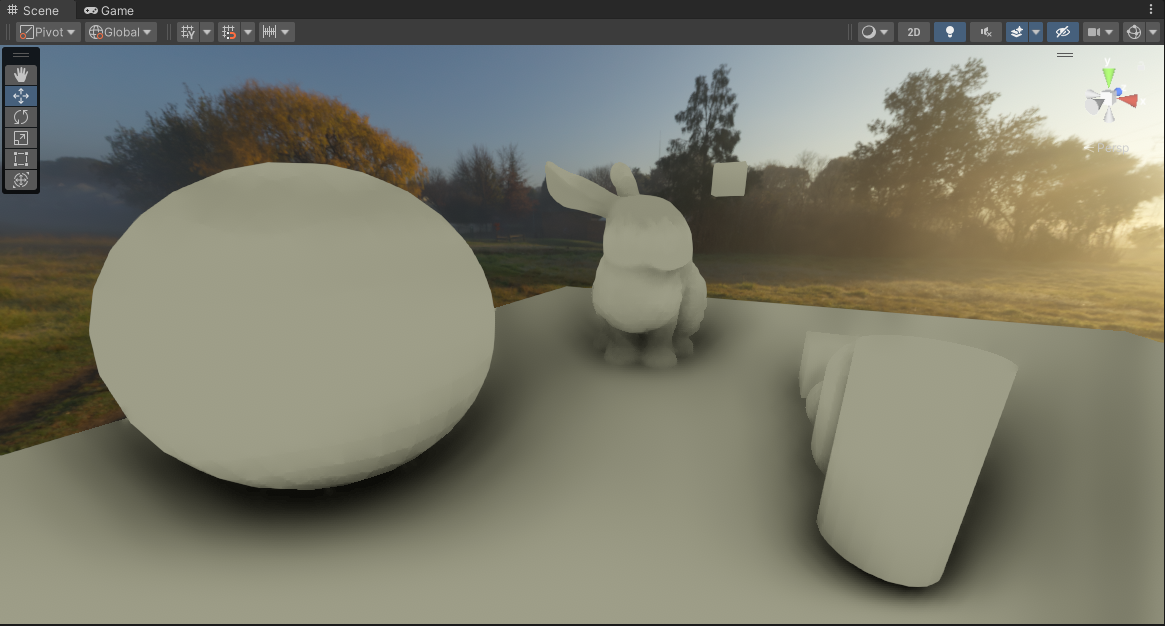
 Spherical Harmonics Order 0 (1 total coefficent)
Spherical Harmonics Order 0 (1 total coefficent)
 Scene Wireframe
Scene Wireframe
I shared the wireframe here to show the scene since you wouldn’t be able to make it out otherwise. But with how this scene is setup, having a single color is not enough to light these objects correctly.
Things like occlusion of course could be used to help with shading just like we tried before…
 Spherical Harmonics Order 0 (1 total coefficent) + SSAO
Spherical Harmonics Order 0 (1 total coefficent) + SSAO
But as we also saw and learned previously… Occlusion, regardless of what kind of flavor we may be using here (SSAO, Material Occlusion, Lightmaps, etc) is still not enough. More importantly it does not solve the underlying problem of the smeary/blurry lighting. Again this is because we are dealing with just a single color for the lighting.
We need more information than just a single color from our lighting environment. So lets bump the order up so we can gather more data to better shade our scene! With Order 1 we add 3 extra coefficents that are oriented to a specific direction…
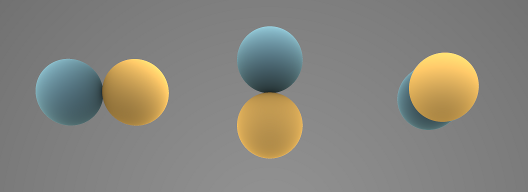 Spherical Harmonics Order 1 (3 coefficents this order introduces)
Spherical Harmonics Order 1 (3 coefficents this order introduces)
This is now where you see the upsides to using spherical harmonics, because each coefficent now can provides us with more detailed information about the lighting environment…
- Spherical Harmonic Coefficent 0 (L = 0, M = 0): Describes the average color of the whole lighting environment.
- Spherical Harmonic Coefficent 1 (L = 1, M = -1): Describes the average left/right lighting color of the environment.
- Spherical Harmonic Coefficent 2 (L = 1, M = 0): Describes the average top/down lighting color of the environment.
- Spherical Harmonic Coefficent 3 (L = 1, M = 1): Describes the average forward/back lighting color of the environment.
At shading time, we take these calculated coefficients, project them to reconstruct the spherical harmonic environment, and then sample it using the surface normal.
| |
 Spherical Harmonics Order 1 (4 total coefficents)
Spherical Harmonics Order 1 (4 total coefficents)
You can see now we can read depth and shapes from the scene now since we are shading with more than just a single color from the environment. Depending on the orentation of the surface we get different colors that corespond to the lighting environment.
All of that just from 4 float3 colors!
 Spherical Harmonics Order 0 and 1 (4 total coefficents)
Spherical Harmonics Order 0 and 1 (4 total coefficents)
Now we could go further and introduce more orders, which would give us better resolution and quality… However introducing more coefficents would make things a little heavier memory wise and even a little more expensive at evaluation time.
Remember that with each new Spherical Harmonic order you introduce a new set of coefficents that makeup that order and need to be sampled.
With Diffuse/Irradiance Lighting, it’s very common to at most use up to Order 1. This is because diffuse lighting tends to always be very blurry and low-frequency. Using more orders on a phenomena that is natrually blurry and low-frequency would be wasteful. (At most Order 2 is used for Diffuse/Irradiance)
So to keep things light and simple, we will just stick with up to Order 1 Spherical Harmonics. I would dive more into detail but just trust me on this :D
Ok fine, so how can we use it?
Spherical Harmonics: How to apply it?
| |
These are the spherical harmonic basis functions, but in order to use these we need to shift things a bit in our original lighting function.
| |
Instead of returning/outputing the final singular color lighting based on the surface position and orientation at a given point… We want to return more data/colors that describe the lighting environment at that specific point.
We shift things to where we switch to calculating the full 360 degree lighting environment from that point (instead of a hemisphere like before) and store that result into SH coefficents that can be sampled later.
| |
Now, in practice though with render targets and fragment shaders we typically only output 1 RGBA color.
But in our case we have these 4 RGB colors that we now need to return? We can’t exactly squeeze 4 RGB colors into a single output RGBA. So how can we output all the data that we need?
I’m going to keep things brief at first, but later I explain the specifics of the packing and optimizations later here, but a short summary is that we can actually do some basic swizzling to pack the 4 RGB colors into just effectively 3 float4’s.
That alleviates the pressure a bit but we still end up with 3 float4s. Well we need to change things in our backend quite a bit to something that would allow us to output more data from a shader. A compute shader can do this, so we move our lighting calculation function into one and at the end of it we output the packed float4 coefficents into 3 render targets simultanoeusly.
| |



Left To Right: SHA (Render Target 0) | SHB (Render Target 1) | SHC (Render Target 2)
I still retain all of the upsampling and filtering passes I had before, but I just do them with each of the SH render targets. (I also moved these to a compute shader)
After upsampling the SH render targets to full resolution, I do an additional final pass where we sample the SH lighting environment using the full resolution scene normal. The code for that just looks something like this…
| |
This is the final lighting result.
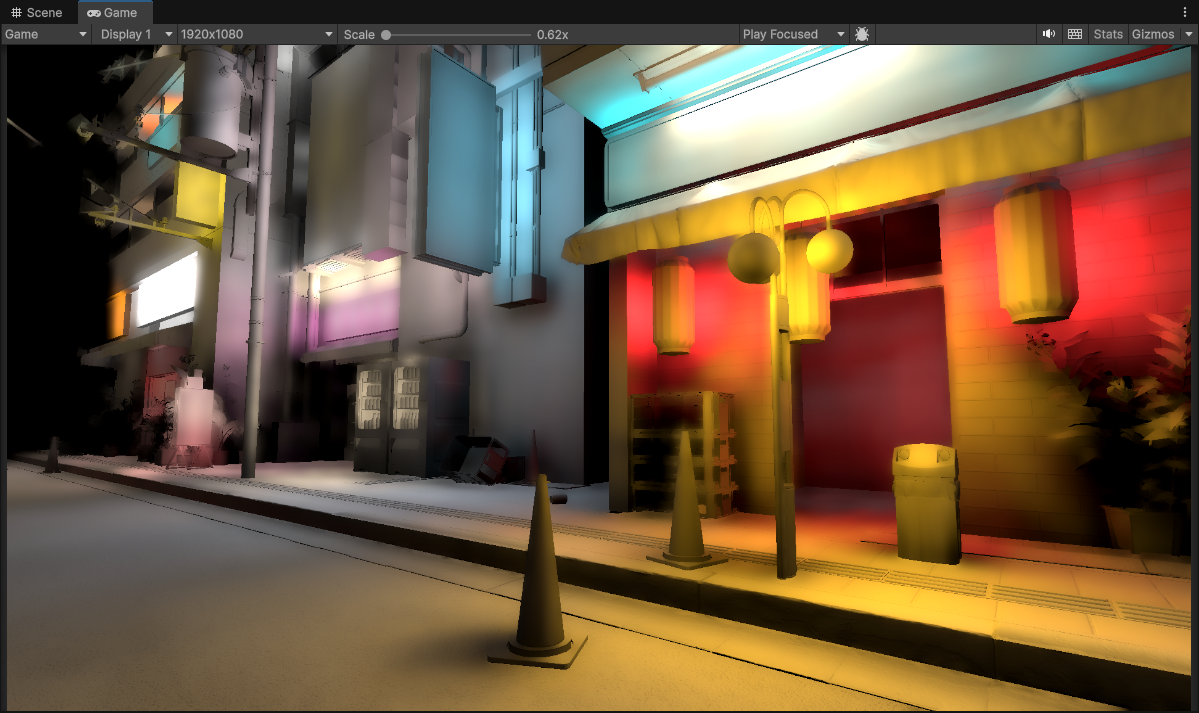 1/8th Resolution (240 x 135) using Spherical Harmonics, Downsampled Buffers and 3 upsample passes (to 1920 x 1080)
1/8th Resolution (240 x 135) using Spherical Harmonics, Downsampled Buffers and 3 upsample passes (to 1920 x 1080)
Woah! We can see now that scene details are retained very well now. Normal maps and granular details are actually visible and no longer overly smeared, and all of the underlying of the scene artwork is kept in tact.
More importantly also the final lighting now is properly convincing at the resolution it is running at. We have full lighting information!


Left: 1/8th Resolution (240 x 135) No SH + Occlusion | Right: 1/8th Resolution (240 x 135) with SH
That pipe I pointed out initally, well now we can make it out pretty well!
We have one more final step, because we still have our occlusion term from before. We can now use it and multiply it with our final upsampled spherical harmonic lighting to get the final lighting results.
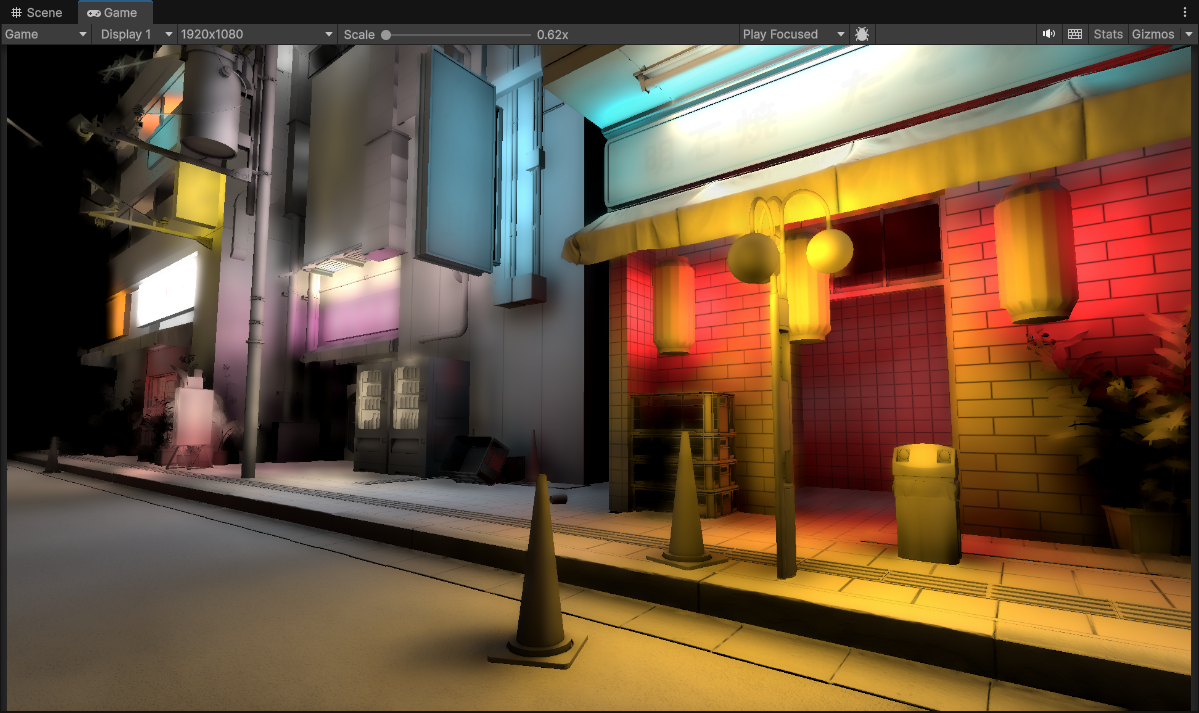 1/8th Resolution (240 x 135) using Spherical Harmonics, Downsampled Buffers and 3 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
1/8th Resolution (240 x 135) using Spherical Harmonics, Downsampled Buffers and 3 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
Voila! It looks pretty good to me. I can make out all of the geometry edges, and even the normal mapped scene details. Temporally it is also pretty stable now, and using the occlusion term here also adds a lot more detail and sharpens up other portions of the image.
This is currently the best I’ve been able to come up with in regards to getting very good and usable results with very low resolution lighting input. Remember, this is all coming from lighting that is calculated at 1/8th screen resolution which originally would have looked like this.
 1/8th Resolution Raw (240 x 135) with no upsampling or downsampling
1/8th Resolution Raw (240 x 135) with no upsampling or downsampling
The best part also is that we can actually drop the resolution even lower, and details will still be almost fully retained.!
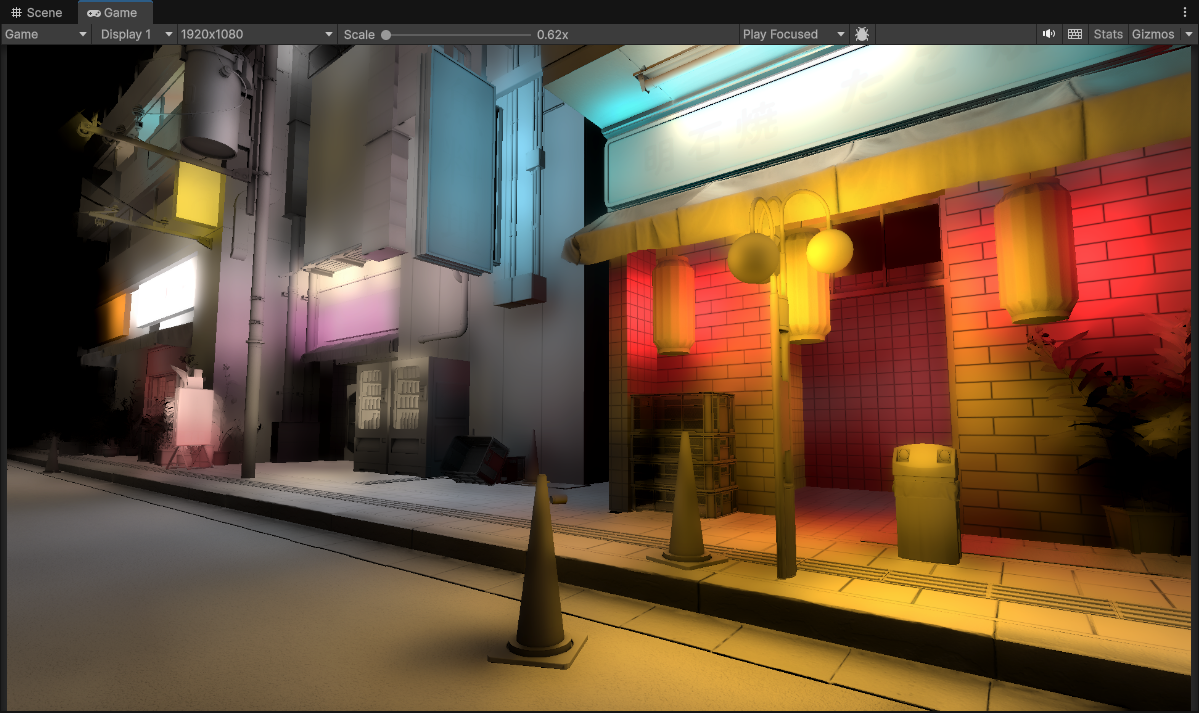 1/16th Resolution (120 x 67) using Spherical Harmonics, Downsampled Buffers and 4 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
1/16th Resolution (120 x 67) using Spherical Harmonics, Downsampled Buffers and 4 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
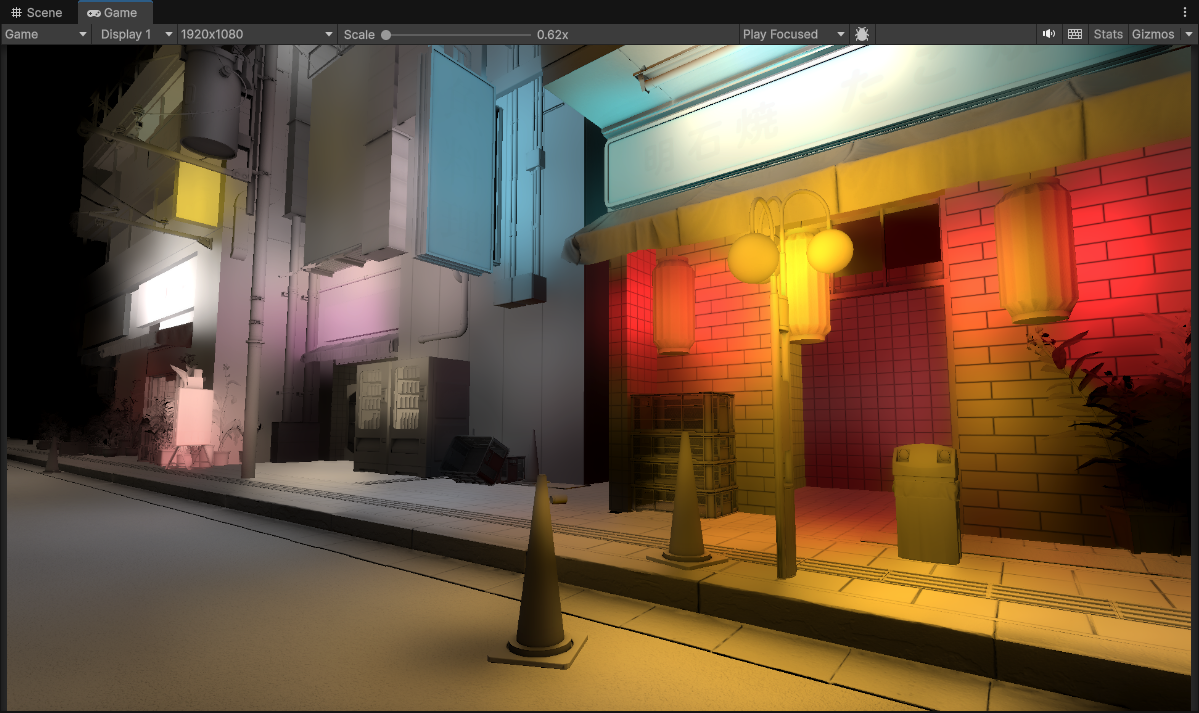 1/32th Resolution (60 x 33) using Spherical Harmonics, Downsampled Buffers and 5 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
1/32th Resolution (60 x 33) using Spherical Harmonics, Downsampled Buffers and 5 upsample passes (to 1920 x 1080) + Full Resolution Material Occlusion
Spherical Harmonic Comparisons
NOTE: These screenshots don’t have occlusion term factored in, we are just comparing the raw upsampled voxel cone trace with and without spherical harmonics.


Left: 1/8th Resolution (240 x 135) No Spherical Harmonics (3 upsample passes) | Right: 1/8th Resolution (240 x 135) With Spherical Harmonics (3 upsample passes)


Left: 1/16th (120 x 67) Resolution No Spherical Harmonics (4 upsample passes) | Right: 1/16th Resolution (120 x 67) With Spherical Harmonics (4 upsample passes)


Left: 1/32th Resolution (60 x 33) No Spherical Harmonics (5 upsample passes) | Right: 1/32th Resolution (60 x 33) With Spherical Harmonics (5 upsample passes)
Spherical Harmonic Optimizations: Compute Shader
With my inital setup with spherical harmonics, I ran the lighting calculation fragment shader effectively 3 times for each of the spherical harmonic render targets. In addition the upsampling passes would also get multiplied since each of SH render targets needed upsampling to full resolution.
For inital prototyping and proof of concept it worked fine, but this definetly was not ideal and had some performance degredations.
One of the things I did to alleviate this was to move both the main lighting calculation, and the upsampling pass into compute shader kernels.
That way I just execute the main lighting compute shader kernel once, and that would allow me to simultanoeusly write to the 3 SH render targets that I have (Rather than needing to run the lighting calculation fragment shader 3 times). The same also for the upsampling kernel, simultaneously upsampling the 3 render targets.
| |
Spherical Harmonic Optimizations: Render Target Packing
I also mentioned that I had 3 SH render targets. Which might not make sense considering we are dealing with Order 1 Spherical Harmonics which leaves you with 4 float3’s.
- RGBA Render Target 0
- R: L0.r
- G: L0.g
- B: L0.b
- A: (Unused)
- RGBA Render Target 1
- R: L1X.r
- G: L1X.g
- B: L1X.b
- A: (Unused)
- RGBA Render Target 2
- R: L1Y.r
- G: L1Y.g
- B: L1Y.b
- A: (Unused)
- RGBA Render Target 3
- R: L1Z.r
- G: L1Z.g
- B: L1Z.b
- A: (Unused)
You could have 4 render targets, but that is a bit wasteful memory wise. Turns out we can just pack those 4 float3’s into 3 float4’s with some basic swizzling. (moving each of the components around)
NOTE: The render targets are RGBA64. Each component is 16 bit half precison, not 8 bit because we are dealing with lighting. We need HDR (High Dynamic Range) for proper shading results.
- RGBA Render Target 0
- R: L0.r
- G: L0.g
- B: L0.b
- A: L1X.r
- RGBA Render Target 1
- R: L1X.g
- G: L1X.b
- B: L1Y.r
- A: L1Y.g
- RGBA Render Target 2
- R: L1Y.b
- G: L1Z.r
- B: L1Z.g
- A: L1Z.b
If you want also you might even go further and shrink things down to 2 Render Targets by trading color accuracy for luminance. In this case the first Order 0 coefficent remains a full RGB, but Order 1 coefficents store luminance rather than a full RGB color.
- RGBA Render Target 0: (L0.r, L1.g, L1.b, L1X)
- R: L0.r
- G: L0.g
- B: L0.b
- A: L1X
- RGHalf Render Target 1: (L1Y, L1Z)
- R: L1Y
- G: L1Z
There are likely other clever packing schemes that exist, you are welcome to try them and if it works for you, then do it! (If you also know of any other additional techniques for this please let me know! I’m still on the lookout)
Spherical Harmonic Bonuses
Another bonus of said effects is that since we have information on the lighting environment beyond just a single color now for every pixel.
With spherical harmonics we can actually do a trick to where we can calculate the dominant direction of light from the SH environment. This dominant direction vector can then be used to derive a specular highlight term that can enhance the quality of our global illumination reflection buffer!
The dominant direction also in theory can also be used for potentially more things (like localized contact shadows, or micro shadows, etc).
Future: How to go even further and beyond?
Where to go from here of course?
At this point I am mostly satisified with the results, but I am still actively exploring techniques or other avenues to improve results even further.
A big part of global illumination is specular/reflections. We only looked at diffuse/irradiance here, but often reflections are handled in a seperate pass. SSR is a potential solution here (and a common industry one) but that has obvious drawbacks with only being a screen-space effect. It would be ideal if both diffuse and specular/reflections could be done once in a single pass.
At the time of writing I have my eyeballs set on radiance caching with octahedron maps.
Spherical harmonics are great but don’t contain enough information to store radiance (or reflection). Having effectively a low resolution cubemap per pixel (or area) would be more useful. That is where octahedral mapping can come in. That octahedron map can be used for reflections directly, and diffuse/irradiance can also be derived from it using spherical harmonics just like we did before.
The only issue with the approach is that memory wise it will be considerably heavier, needing to store effectively a cubemap per pixel. Potentially more expensive also since now you are juggling alot more data, and you need very good probe interpolation across pixels.
I do have a prototype working, but it needs alot more work before I’d consider it to be usable and viable. Probe interpolation currently being a difficult problem to solve well.
References / Sources
List of references that helped with my implementations and understanding.
By: David Matos